接了十几个企业级 Agent,入门就 6 步
June 24th, 2026
前言
我为公司业务接入了数十个企业级 Agent,做下来发现 Agent 开发真的很简单。
这篇我就用一个查订单的 Agent,从最简单的实现开始一步步往上加,带你看它怎么长成一个能在公司里真正用起来的东西。
什么是 Agent, 什么是 Harness
这个 Harness 最近概念很火,先把 Agent 这个词拆开,一个公式就能说清楚:
Agent = Model + Harness
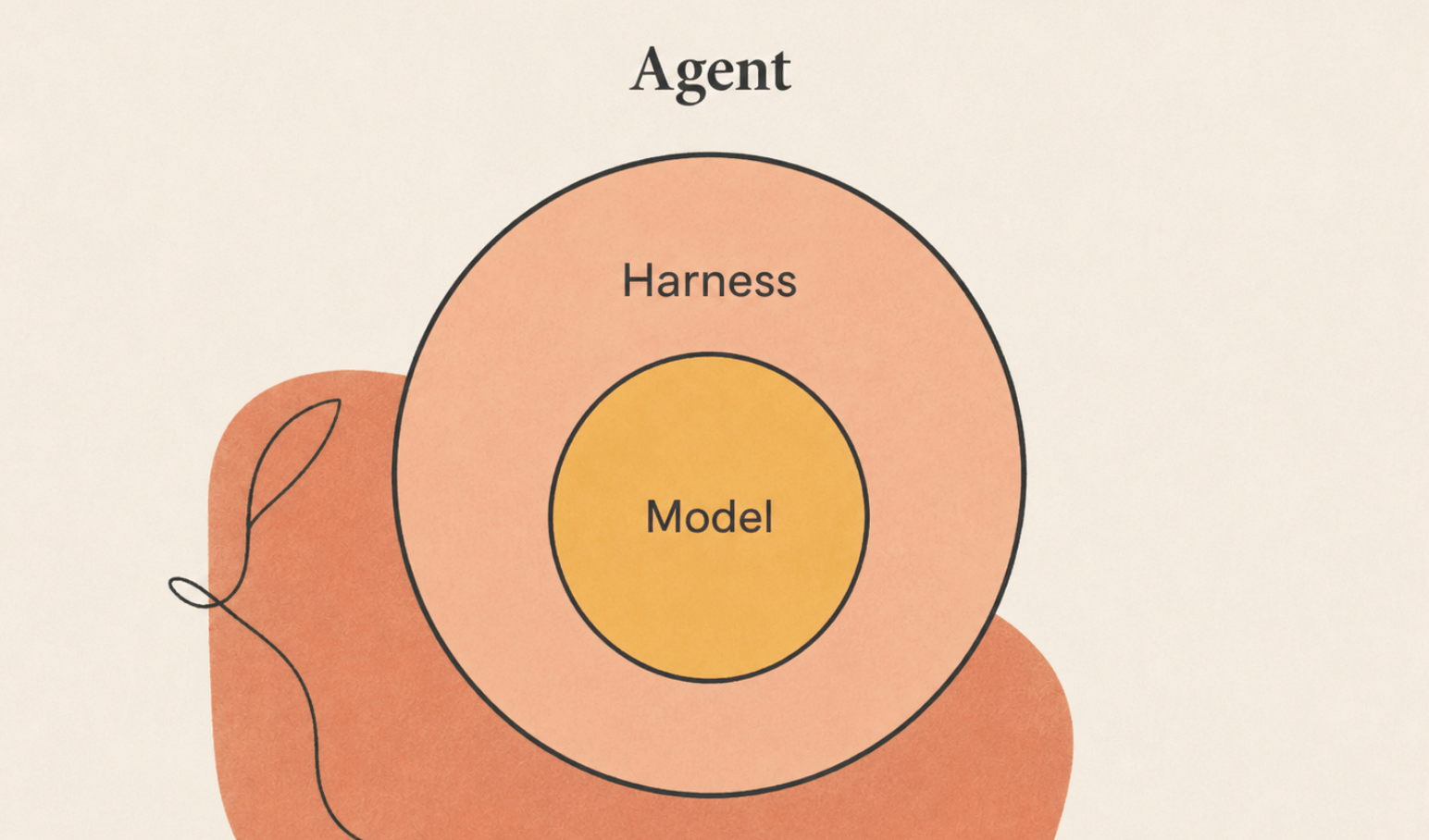
Model 就是大模型 Harness 这个词原意是马具,就是套在马身上那一圈缰绳、马鞍。放到 Agent 这里,它指的是模型周围的一切脚手架:
- 提示词
- Tool 定义
- 循环控制
- 校验和错误恢复
- 人机协同
模型本身只负责思考,至于怎么让它稳稳地调工具、出错了能兜底,全靠 Harness 这一圈工程。所以你开发 Agent,其实是在搭建 Harness 。
实现一个最简单的查询订单 Agent
一个能跑的 Agent,拆开看就三样东西:
- model:用哪个模型
- 系统提示词:告诉它是谁、要干什么
- tools:它能调用哪些工具
代码长这样:
const agent = new ToolLoopAgent({
model: provider.chat("kimi-k2.5"),
// 系统提示词
instructions: SystemPrompt,
// 工具列表
tools: {
searchOrders,
askForConfirmation,
},
})
PS: ToolLoopAgent 是 Vercel 的 AI SDK 用来构建 Agent 的类,后面也会以使用 AI SDK 为例子
就这么点东西,一个 Agent 就成立了。
是不是比想象中简单?它现在已经能听懂“帮我查一下上周那个订单”,然后决定去调 searchOrders 这个工具。
当然这只是个雏形。接下来每加一个真实业务里的需求,我都会带出一个新概念。
工具调用
了解工具调用的概念
工具调用这个概念,刚接触的时候有点抽象。我用一个模拟的流程来说明。
最容易踩的认知误区是:很多人以为模型自己去调了接口,其实不是。
模型干的事情很单纯,它只是返回一段“我想调用某个工具”的信息。比如用户说要查订单,模型会吐出这么一段东西:
{
"type": "tool-call",
"toolName": "searchOrders",
"args": { "orderNo": "SO20260624001" }
}
它没有真的去查库,它只是告诉你:我想调 searchOrders,参数是这个订单号。
真正去执行的,是中间那层 Agent 服务。它拿到模型这段调用信息,解析出要调哪个工具,再去调真实的后端接口,拿到结果塞回对话里,模型才能接着往下说。
整个来回是这样一个循环:
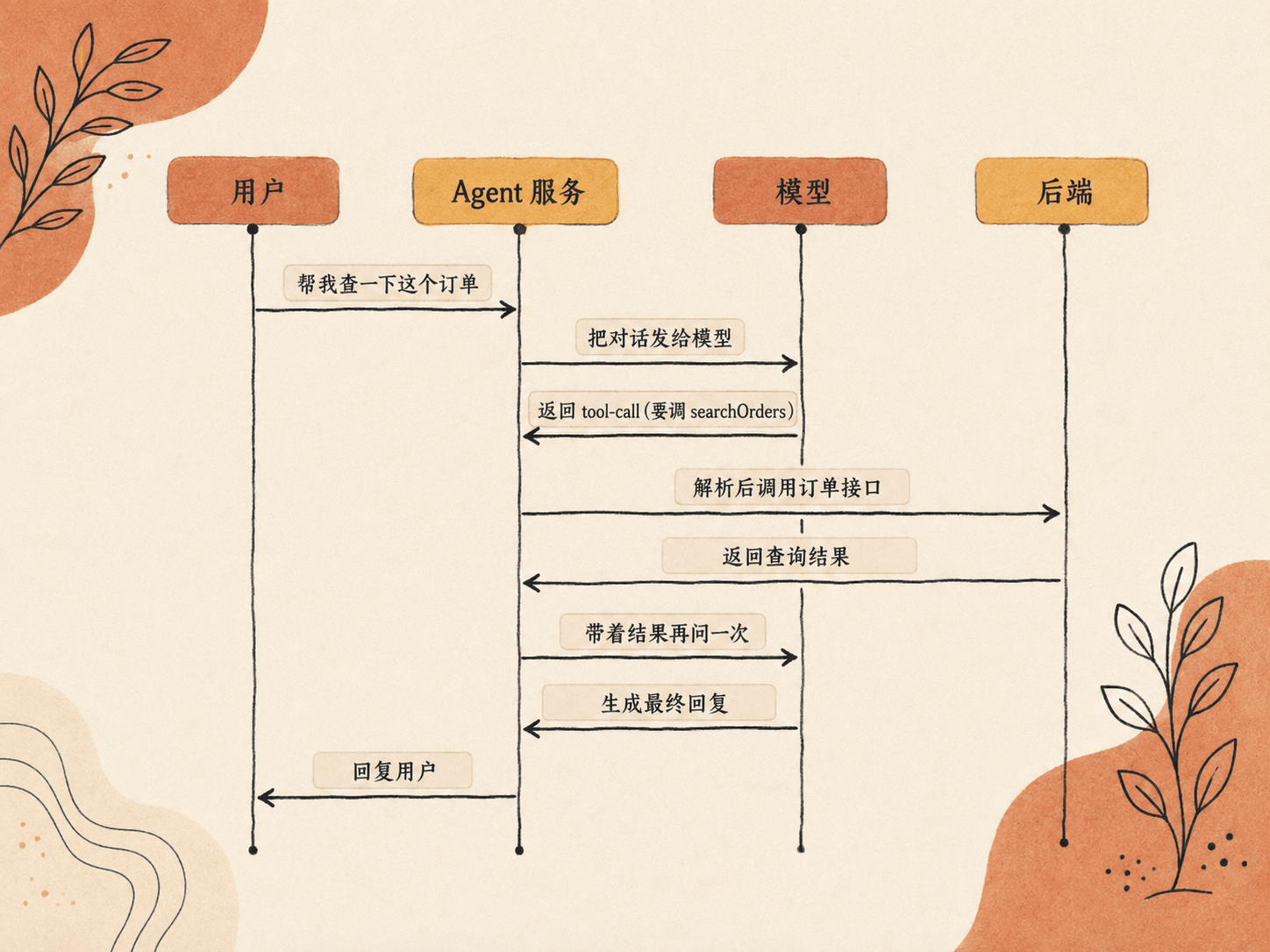
这张图比我讲一堆话都清楚,对着箭头走一遍就明白了。
区分服务端和客户端
同样是工具调用,在哪执行,差别很大。
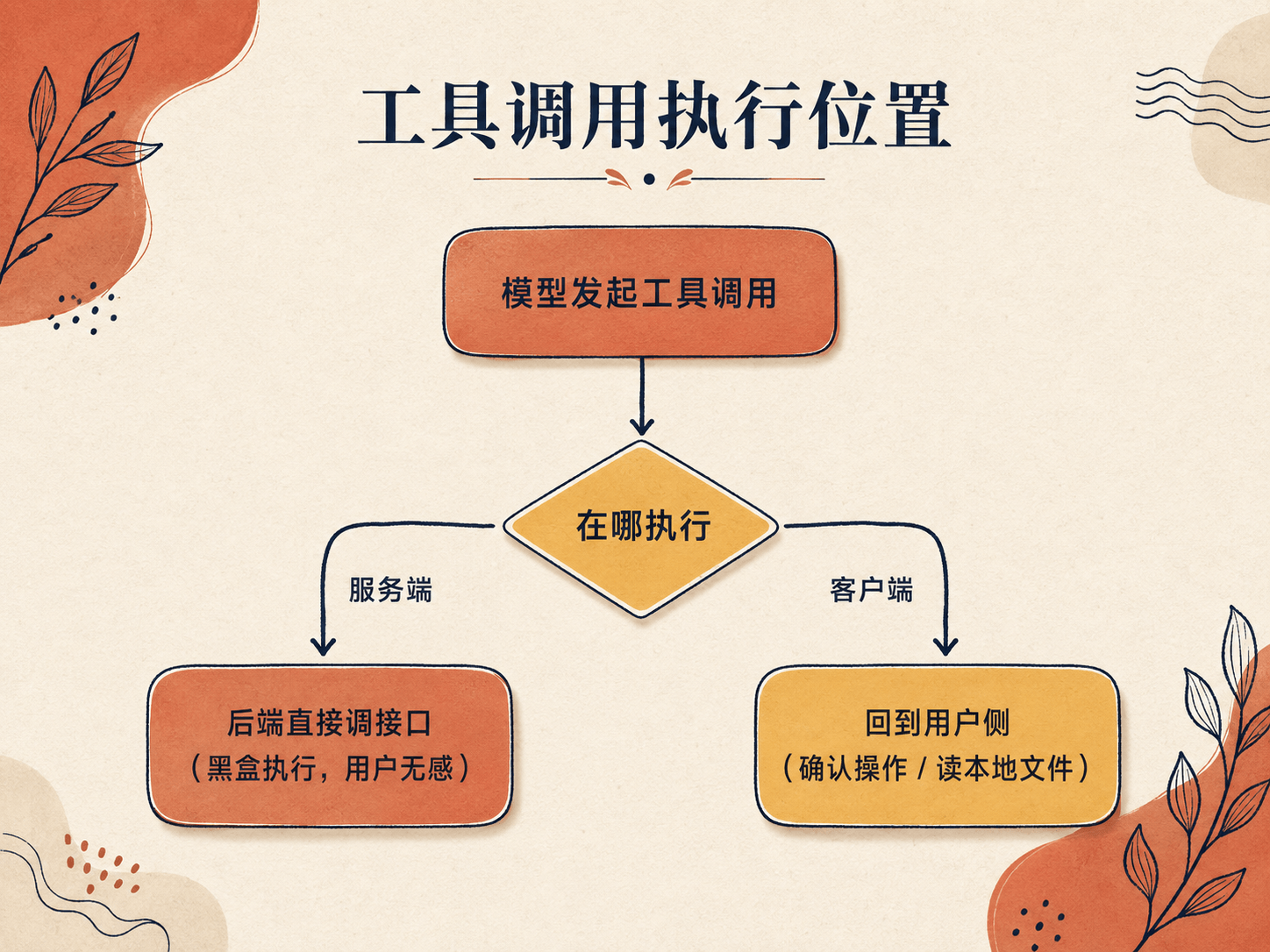
主要看几个点:谁来执行、数据在哪、要不要用户参与。据此分成两类。
客户端执行,通常是需要在用户那一侧交互的场景,典型有两种:
- 需要用户确认的操作
- 本地文件相关的调用
这些都绕不开客户端,得让用户在那边参与一下。
服务端执行,就是后端直接调接口。对模型和用户来说全是黑盒,调用、执行、返回都在你的后端里走完。查订单就是典型的服务端执行。
所以同一次工具调用,落在服务端还是客户端,走的是完全不同的两条路。
什么是 Tool UI
Tool UI,就是给工具调用的结果配上专门的界面,而不是只把结果干巴巴地用文字吐出来。一个 Agent 如果只会一行行吐文字,体验很差,所以你最好为每种工具调用都设计好看的 UI。
比如下面这几种:
用户问答确认界面,让用户点一下确认再继续。
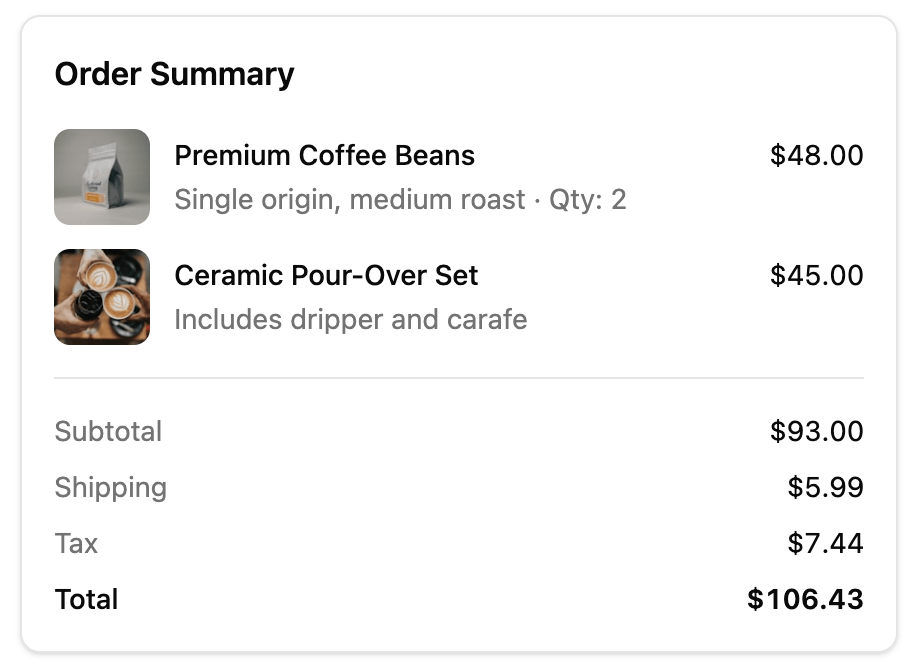
卡片式布局,把订单的汇总信息排清楚。
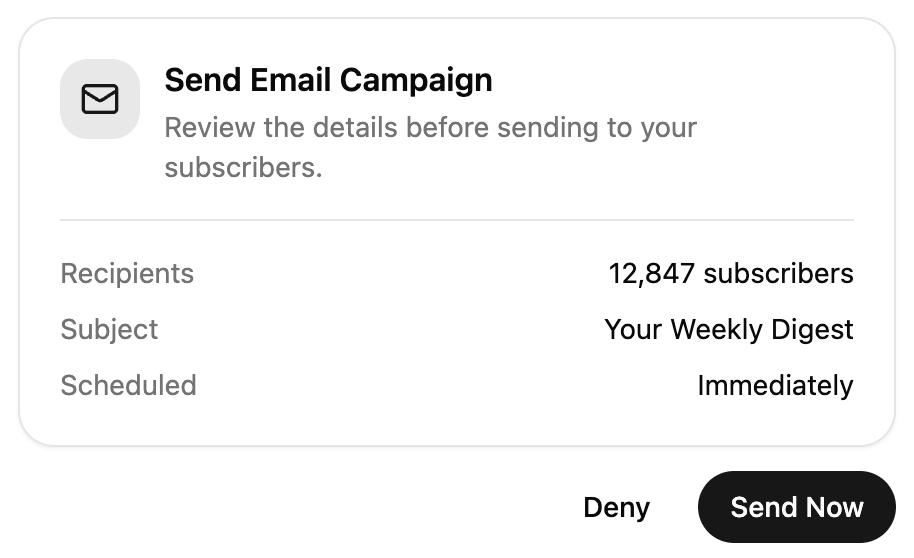
发送邮件确认。
这类 Tool UI 就是用代码写出来的组件。除了好看,UI 上的按钮还能实现更多交互。
举个例子。有些 AI 接入了下单功能,比如创建外卖订单。当系统生成外卖订单的 UI 之后,用户可以直接在这个 UI 里点击下单。后面这些点击操作其实跟 AI 已经没关系了,它就是一个生成好的、确定性的 UI。
跟它对应的是生成式 UI,每次都由 AI 现场组装。好处是灵活,什么场景都能临时拼出界面来;坏处是不太可控,AI 这次拼成什么样你没法完全保证。
这两种各有取舍。下单、确认这类关键操作,最好用确定性 UI,稳、结果可控;至于那些形态不固定、又不太敏感的展示,生成式 UI 会灵活很多。
通用级别的工具调用
有一类工具调用是跨场景都能复用的,我把它叫通用级别的工具。
常见的有这么几种能力:
- 询问用户并给出选择
- 调取业务接口
- 调取系统接口
其中“询问用户”很值得单独说。当模型信息不够、需要用户做个选择时,它可以组装成一个询问界面,把选项摆给用户。等用户选完,再带着这个选择进入下一轮 Loop。
这样 Agent 就不是一条道跑到黑,而是能在中途停下来问你一句“你是要查这个还是那个”。
接入业务系统的工具取舍
接企业系统的时候,会碰到一个很现实的选择:
每个接口做成一个 tool,还是一个 tool 里组装各种接口?
我更倾向后者。两种都能做,而且都得做懒加载,也就是用到了才加载,别一上来把所有接口都塞给模型。
具体怎么落地,对应两种做法。
第一种,每个接口各做成一个独立的 tool,但不一上来全给模型,而是先用一个“加载器”告诉模型有哪些接口可用,等真要用了,再把对应的 tool 动态注册进来。
第二种,也是我倾向的,是从头到尾只保留一个 tool,里面先列一份接口清单;模型真要调某个接口时,才把那个接口的文档喂进去,交给它调度。
我为什么倾向只用一个 tool?因为 tool 数量过多,对 AI 的性能影响比较大。你一股脑塞几十个 tool 进去,模型选起来又慢又容易选错。
所以用一个 tool 来做渐进式加载接口文档,先告诉模型这个工具大概能干嘛,等用户真的要查订单了,再把查订单的接口文档局部加载进来喂给它。这是我觉得在企业级实战里更合理的一种做法。
Human-in-the-loop
什么是 Human-in-the-loop?
Agent 自己在循环里跑的时候,碰到需要用户确认的操作,比如确认订单、修改文件,就会停下 loop,等用户点头再继续。不光是危险操作,只要该让用户拍板的,都算。
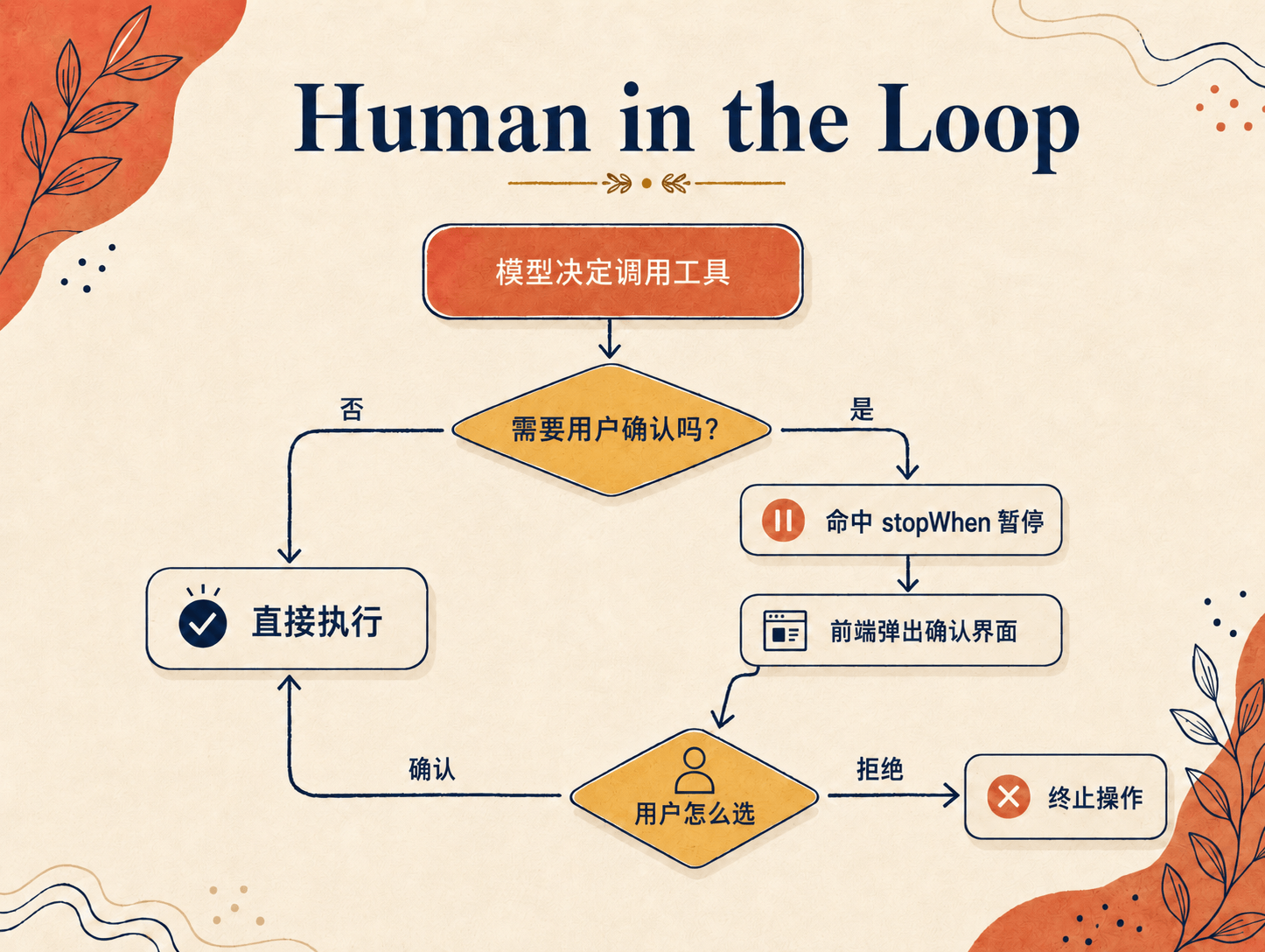
那在代码里怎么做?还记得前面工具调用那个循环吗,关键就是让它在该停的地方停下来。靠 stopWhen 这个停止条件,配一个特殊工具 askForConfirmation:
const agent = new ToolLoopAgent({
model: provider.chat("kimi-k2.5"),
instructions: SystemPrompt,
stopWhen: [
// 模型一旦想调 askForConfirmation,就停下来等用户
hasToolCall("askForConfirmation"),
// 兜底:最多跑 15 步,防止万一陷进死循环
stepCountIs(15),
],
tools: {
searchOrders,
askForConfirmation,
},
})
askForConfirmation 没有 execute 函数,不干任何事,只是个停止信号。模型判断这步需要确认就调它,stopWhen 一抓到,循环立刻暂停,前端弹出确认界面;用户点了确认,再把结果塞回去往下跑。
至于代码里那行 stepCountIs(15),跟人工确认没关系,纯粹是兜底,防止循环万一停不下来。
不过光有这个工具还不够。模型不会自己知道什么时候该停,你得在系统提示词里写清楚,什么情况下调它。比如:
以下情况,调用 askForConfirmation 等用户确认:
1. 用户要确认订单时,把订单信息整理出来,让用户确认后再提交。
2. 用户给的信息比较模糊时,调用它,列出可能的选项,让用户选一个再继续。
这其实对应两种用法:一种是执行前先确认,比如确认订单;另一种是反过来问用户、列几个选项让他选,也就是前面通用工具讲的“询问用户”。
企业级权限控制
企业级的控制,可以分多层来做。这是接入业务系统时最常见的问题之一。
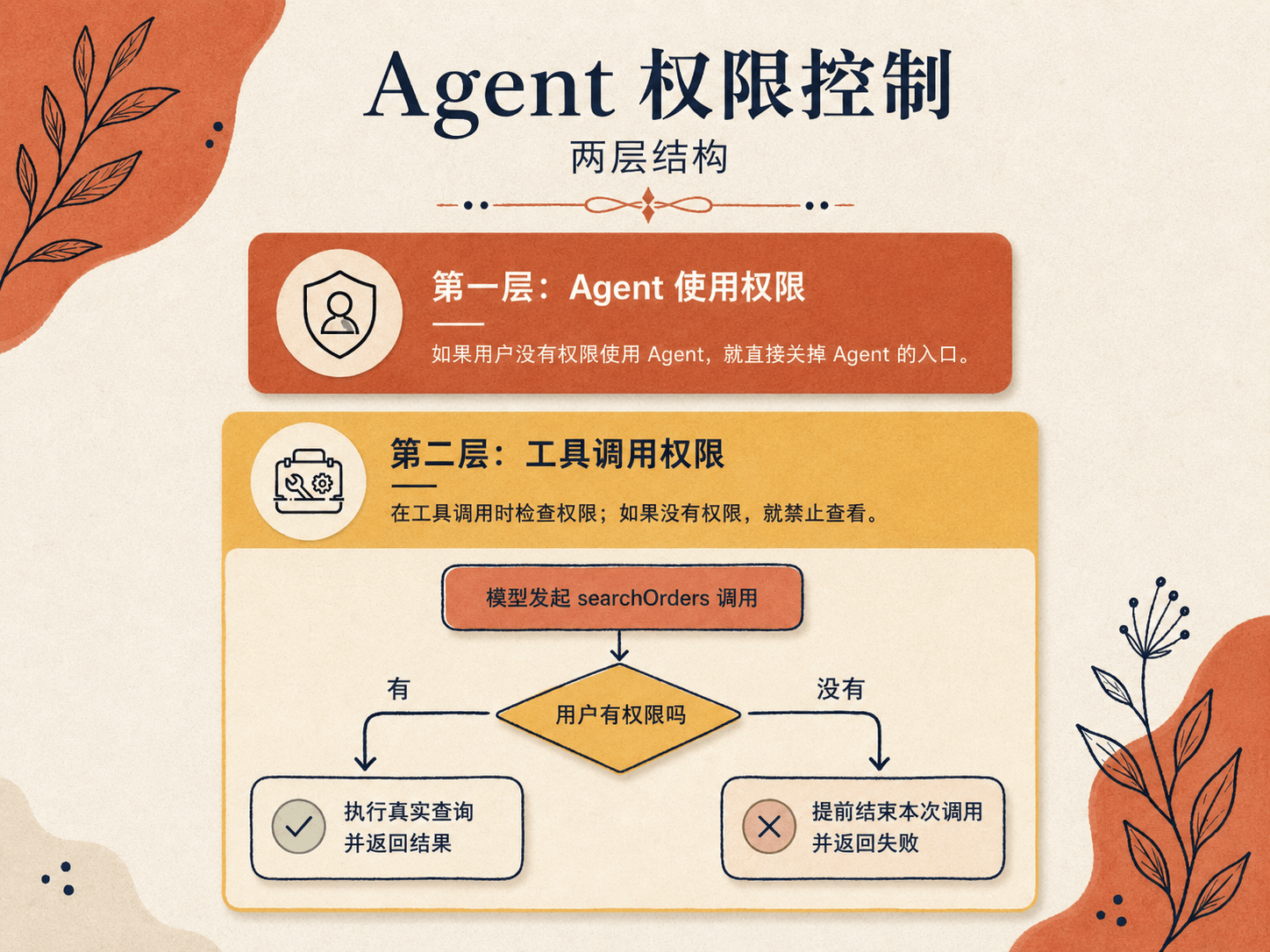
第一层,Agent 使用权限。
先得判断哪些用户有资格用这个 Agent。不是谁都能用,先在入口把人筛一遍。
第二层,数据访问权限。
Agent 去调工具取数据的时候,分两种情况。
第一种,公司业务系统本身的权限管理已经做得很完善。那其实没什么问题,工具直接复用业务系统的权限就行。
第二种,接口本身没做权限管理,谁调都能看到全部数据。但实际上有些数据,某些用户是不该看到的。这时候就得在做工具调用时,再加一层权限判断接口。
const searchOrders = tool({
// ...省略入参定义
execute: async (args, { userInfo }) => {
// 工具真正执行前,先查这个用户有没有权限看这条数据
const allowed = await checkDataPermission(userInfo, args.orderNo)
if (!allowed) {
// 没权限就提前结束本次调用,返回失败
return { success: false, error: "你没有权限查看该订单" }
}
return await realSearchOrders(args)
},
})
逻辑很简单:执行前先检查,发现用户没有权限,就提前结束掉这次工具调用,返回一个失败结果。
这一层千万别省。我见过只靠提示词约束权限的做法,结果模型一旦被用户绕话术诱导,就替他越权读到了不该读的数据,而且日志里看着还特别“合法”。所以权限得在代码里挡死,光靠提示词靠不住。
接入业务系统的接口处理
标准接口:定义清晰、字段有意义
传统接口是给人和后端系统用的,AI-first 接口是给 LLM 看的。
差别在哪?给 LLM 看的接口,要像写给一个聪明但完全没有上下文的实习生一样,详细、规范、无歧义。
几个原则:
- 入参清晰简洁,不要让 AI 去猜
- 每个字段的含义都明确写出来
- 字段定义在各个接口之间保持一致
未来新做的接口,都应该往这个方向设计。AI 调起来顺,出错率自然就低。
历史接口:包装一层 Wrapper 再接入
问题是,公司里大量的历史接口,没法推倒重写,怎么办?
只能加一个中间层。
我暴露给 AI 的这一层,也就是 Tool 调用的部分,可能就只有那么几个干净的字段。而实际调用业务接口时要传的一堆字段,全都在代码实现里面包掉了。接口返回的结果,同样在这一层里包一遍,再给到 AI。
这样一来,AI 看到的永远是一个清爽、好理解的接口,脏活累活都被 Wrapper 这一层吃掉了。AI 更容易分辨该传什么、该怎么调,你也不用去动那些动不得的老接口。
代价是你得多养一层 Wrapper,但比起去重写那些老接口,这点活划算多了。
结尾
回头看,一个企业级 Agent 的雏形,就是这么一层层加起来的。
从最简单的 model 加提示词加 tools 开始,然后是工具调用、区分客户端和服务端、Tool UI,再到 Human-in-the-loop、多层权限控制、业务接口的接入处理。
每一层,都对应着企业落地时一个绕不开的真实问题。
如果你也想给自己公司接一个 Agent,我的建议是:从一个只读、低风险的场景开始,比如查询类,先把这套链路在小范围里跑通,再往上加复杂度。
如果你觉得这篇文章对你有帮助,欢迎点赞、分享,你的支持是我持续创作的最大动力!